

이 글은 스터디를 참여하면서 학습한 내용을 중심으로 Kubernetes를 정리하는 연재 글이다. '24단계 실습으로 정복하는 쿠버네티스' 도서 내용을 중심으로 정리하고 있다. 스터디 진도에 맞춰 4~5개의 글을 작성 할 예정이다.
이번 글에서는 Kubernetes의 모니터링, 로깅 시스템을 알아보겠다. 쿠버네티스의 수많은 파드의 메트릭을 확인하고, 문제가 있을 때 로깅을 어떻게 할 수 있을까? 포스팅에서는 모니터링과 로깅을 프로메테우스 (Prometheus), 그라파나(Grafana), 로키(Loki)를 사용해본다.
1. 실습환경 배포
kops 환경을 배포해준다. kops 배포는 [PKOS] kOps를 사용한 Cluster 설치와 기본 Kubernetes 관리 방법 글에 자세히 기술되어 있다. 저번 실습과 같이 이번에도 CPU를 많이 요구하는 시스템으로 비교적 높은 사양의 인스턴스 타입을 사용할 예정이다. 마스터 노드는 t3.medium / 워커 노드는 c5a.2xlarge를 사용했다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
# YAML 파일 다운로드
curl -O https://s3.ap-northeast-2.amazonaws.com/cloudformation.cloudneta.net/K8S/kops-oneclick-f1.yaml
# CloudFormation 스택 배포 : 노드 인스턴스 타입 변경 - MasterNodeInstanceType=t3.medium WorkerNodeInstanceType=c5d.large
aws cloudformation deploy --template-file kops-oneclick-f1.yaml --stack-name mykops --parameter-overrides KeyName=ygpark SgIngressSshCidr=$(curl -s ipinfo.io/ip)/32 MyIamUserAccessKeyID=AKIA6NUKWRMLEXRDE3VA MyIamUserSecretAccessKey='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' ClusterBaseName='ygpark.net' S3StateStore='ygpark-s3' MasterNodeInstanceType=t3.medium WorkerNodeInstanceType=c5a.2xlarge --region ap-northeast-2
# CloudFormation 스택 배포 완료 후 kOps EC2 IP 출력
aws cloudformation describe-stacks --stack-name mykops --query 'Stacks[*].Outputs[0].OutputValue' --output text
13.125.192.64
# 13분 후 작업 SSH 접속
ssh -i /mnt/c/vswork/_pkos2/secret/ygpark.pem ec2-user@$(aws cloudformation describe-stacks --stack-name mykops --query 'Stacks[*].Outputs[0].OutputValue' --output text)
# EC2 instance profiles 에 IAM Policy 추가(attach) : 처음 입력 시 적용이 잘 안될 경우 다시 한번 더 입력 하자! - IAM Role에서 새로고침 먼저 확인!
aws iam attach-role-policy --policy-arn arn:aws:iam::$ACCOUNT_ID:policy/AWSLoadBalancerControllerIAMPolicy --role-name masters.$KOPS_CLUSTER_NAME
aws iam attach-role-policy --policy-arn arn:aws:iam::$ACCOUNT_ID:policy/AWSLoadBalancerControllerIAMPolicy --role-name nodes.$KOPS_CLUSTER_NAME
|
cs |
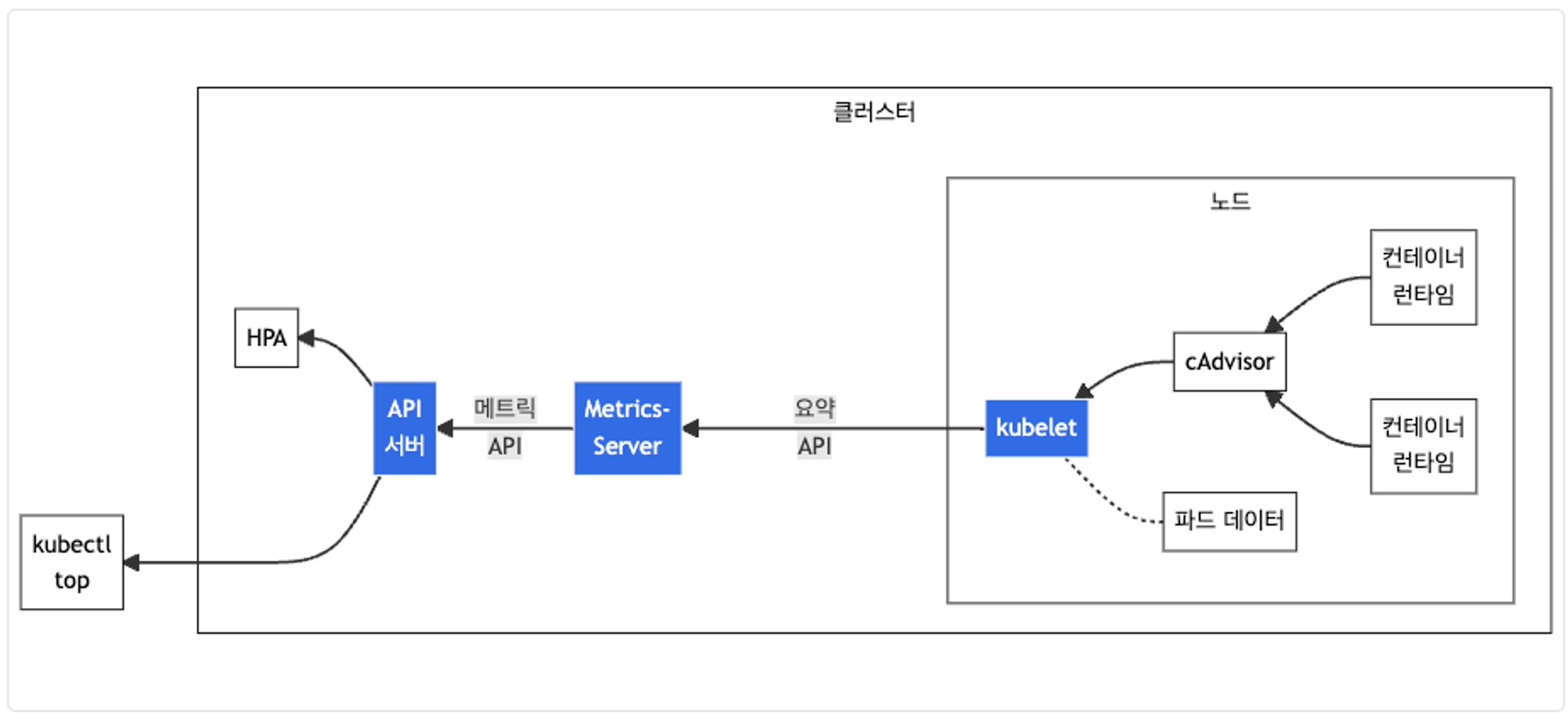
리소스 메트릭 파이프라인
쿠버네티스의 메트릭 수집을 알아보자. 아래 그림을 보면 노드에 cAdvisor 데몬이 떠있다. cAdvisor은 kubelet에 포함된 컨테이너 메트릭을 수집, 집계, 노출하는 데몬이다. metrics-server가 노드 내부의 kubelet으로부터 리소스 메트릭을 수집한다. kubectl top 명령을 이용하여 리소스 메트릭을 볼 수도 있다.
2. 프로메테우스 (Prometheus)
프로메테우스는 SoundCloud에서 개발한 오픈소스 모니터링, 알림 시스템이다. 쿠버네티스에 사용하기 가장 좋은 툴이고, 프로메테우스 로고는 쿠버네티스와 공통점이 많지만 쿠버네티스를 위해 만들기 시작한 것은 아니라고 한다. 그래도 결과적으로 모두가 인정하는 최적의 쿠버네티스 모니터링 툴이다.
프로메테우스는 TSDB (시계열 데이터베이스)을 적재하여 모니터링을 하고, PromQL이라는 언어로 SQL 쿼리하듯 프로매틱 방식으로 확인할 수 있다. 메트릭을 수집하는 service discovery 지원해서 자동적으로 메트릭 타겟을 등록한다.
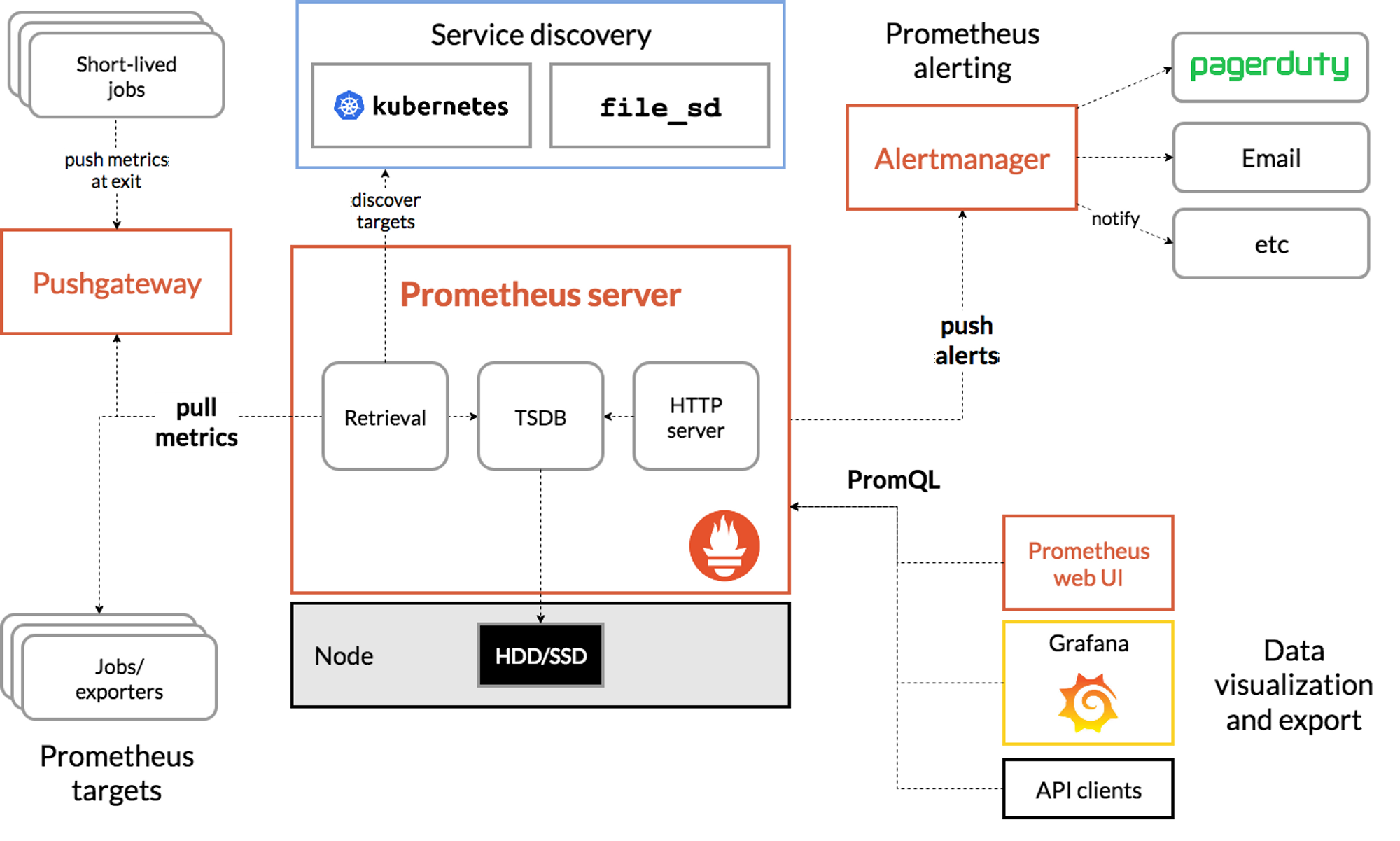
구성요소
- the main Prometheus server which scrapes and stores time series data
- client libraries for instrumenting application code
- a push gateway for supporting short-lived jobs
- special-purpose exporters for services like HAProxy, StatsD, Graphite, etc.
- an alertmanager to handle alerts
- various support tools
프로메테우스-스택 설치
모니터링에 필요한 여러 요소를 하나의 스택으로 제공한다. 정책 룰 Prometheus rules, 그라파나 등이 포함되어 있다.
파라미터 파일에는 인그레스 ALB로 노출하고, 타임존 설정과, admin Password를 설정한다. retention / retentionSize은 디스크 용량이 꽉찰 수 있으니 꽉차면 5일 된 것 부터 삭제하도록 설정되어 있다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
|
# 모니터링
kubectl create ns monitoring
watch kubectl get pod,pvc,svc,ingress -n monitoring
# 사용 리전의 인증서 ARN 확인
CERT_ARN=`aws acm list-certificates --query 'CertificateSummaryList[].CertificateArn[]' --output text`
echo "alb.ingress.kubernetes.io/certificate-arn: $CERT_ARN"
alb.ingress.kubernetes.io/certificate-arn: arn:aws:acm:ap-northeast-2:991354587926:certificate/e80b57ba-b808-4390-b17e-c31d4828d29b
# 설치
helm repo add prometheus-community https://prometheus-community.github.io/helm-charts
# 파라미터 파일 생성
cat <<EOT > ~/monitor-values.yaml
alertmanager:
ingress:
enabled: true
ingressClassName: alb
annotations:
alb.ingress.kubernetes.io/scheme: internet-facing
alb.ingress.kubernetes.io/target-type: ip
alb.ingress.kubernetes.io/listen-ports: '[{"HTTPS":443}, {"HTTP":80}]'
alb.ingress.kubernetes.io/certificate-arn: $CERT_ARN
alb.ingress.kubernetes.io/success-codes: 200-399
alb.ingress.kubernetes.io/group.name: "monitoring"
hosts:
- alertmanager.$KOPS_CLUSTER_NAME
paths:
- /*
grafana:
defaultDashboardsTimezone: Asia/Seoul
adminPassword: prom-operator
ingress:
enabled: true
ingressClassName: alb
annotations:
alb.ingress.kubernetes.io/scheme: internet-facing
alb.ingress.kubernetes.io/target-type: ip
alb.ingress.kubernetes.io/listen-ports: '[{"HTTPS":443}, {"HTTP":80}]'
alb.ingress.kubernetes.io/certificate-arn: $CERT_ARN
alb.ingress.kubernetes.io/success-codes: 200-399
alb.ingress.kubernetes.io/group.name: "monitoring"
hosts:
- grafana.$KOPS_CLUSTER_NAME
paths:
- /*
prometheus:
ingress:
enabled: true
ingressClassName: alb
annotations:
alb.ingress.kubernetes.io/scheme: internet-facing
alb.ingress.kubernetes.io/target-type: ip
alb.ingress.kubernetes.io/listen-ports: '[{"HTTPS":443}, {"HTTP":80}]'
alb.ingress.kubernetes.io/certificate-arn: $CERT_ARN
alb.ingress.kubernetes.io/success-codes: 200-399
alb.ingress.kubernetes.io/group.name: "monitoring"
hosts:
- prometheus.$KOPS_CLUSTER_NAME
paths:
- /*
prometheusSpec:
podMonitorSelectorNilUsesHelmValues: false
serviceMonitorSelectorNilUsesHelmValues: false
retention: 5d
retentionSize: "10GiB"
EOT
# 배포
helm install kube-prometheus-stack prometheus-community/kube-prometheus-stack --version 45.7.1 \
--set prometheus.prometheusSpec.scrapeInterval='15s' --set prometheus.prometheusSpec.evaluationInterval='15s' \
-f monitor-values.yaml --namespace monitoring
# 확인
## alertmanager-0 : 사전에 정의한 정책 기반(예: 노드 다운, 파드 Pending 등)으로 시스템 경고 메시지를 생성 후 경보 채널(슬랙 등)로 전송
## grafana : 프로메테우스는 메트릭 정보를 저장하는 용도로 사용하며, 그라파나로 시각화 처리
## prometheus-0 : 모니터링 대상이 되는 파드는 ‘exporter’라는 별도의 사이드카 형식의 파드에서 모니터링 메트릭을 노출, pull 방식으로 가져와 내부의 시계열 데이터베이스에 저장
## node-exporter : 노드익스포터는 물리 노드에 대한 자원 사용량(네트워크, 스토리지 등 전체) 정보를 메트릭 형태로 변경하여 노출
## operator : 시스템 경고 메시지 정책(prometheus rule), 애플리케이션 모니터링 대상 추가 등의 작업을 편리하게 할수 있게 CRD 지원
## kube-state-metrics : 쿠버네티스의 클러스터의 상태(kube-state)를 메트릭으로 변환하는 파드
helm list -n monitoring
NAME ps-NAMESPACE REVISION UPDATED STATUS CHART APP VERSION
kube-prometheus-stackps-monitoring 1 2023-03-26 20:14:22.952127125 +0900 KST deployed kube-prometheus-stack-45.7.1 v0.63.0
kubectl get pod,svc,ingress -n monitoring
kubectl get-all -n monitoring
kubectl get prometheus,alertmanager -n monitoring
kubectl get prometheusrule -n monitoring
kubectl get servicemonitors -n monitoring
kubectl get crd | grep monitoring
|
cs |
모니터링을 해보면 알람 매니저 파드가 확인된다. 프로메테우스가 Pull 방식으로 메트릭을 수집한다.
노드 메트릭을 가져올 수 있도록 node-exporter 파드가 각각 뜬다. node-exporter를 보면 노드 ip에 9100포트가 열려있어서 노드 상태정보를 제공한다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
|
Every 2.0s: kubectl get pod,pvc,svc,ingress -n monitoring Sun Mar 26 20:14:53 2023
NAME READY STATUS RESTARTS AGE
pod/alertmanager-kube-prometheus-stack-alertmanager-0 0/2 ContainerCreating 0 7s
pod/kube-prometheus-stack-grafana-5b69bc5b78-5wwhm 0/3 ContainerCreating 0 14s
pod/kube-prometheus-stack-kube-state-metrics-7c44b8c9c4-bz6c9 0/1 Running 0 13s
pod/kube-prometheus-stack-operator-75b7b9747d-jg7lx 1/1 Running 0 13s
pod/kube-prometheus-stack-prometheus-node-exporter-5klpz 1/1 Running 0 14s
pod/kube-prometheus-stack-prometheus-node-exporter-8zgr4 1/1 Running 0 14s
pod/kube-prometheus-stack-prometheus-node-exporter-wfz5w 1/1 Running 0 14s
pod/prometheus-kube-prometheus-stack-prometheus-0 0/2 PodInitializing 0 7s
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/alertmanager-operated ClusterIP None <none> 9093/TCP,9094/TCP,9094/UDP 7s
service/kube-prometheus-stack-alertmanager ClusterIP 100.70.74.236 <none> 9093/TCP 14s
service/kube-prometheus-stack-grafana ClusterIP 100.71.140.15 <none> 80/TCP 14s
service/kube-prometheus-stack-kube-state-metrics ClusterIP 100.66.23.73 <none> 8080/TCP 14s
service/kube-prometheus-stack-operator ClusterIP 100.68.113.165 <none> 443/TCP 14s
service/kube-prometheus-stack-prometheus ClusterIP 100.66.246.217 <none> 9090/TCP 14s
service/kube-prometheus-stack-prometheus-node-exporter ClusterIP 100.66.25.99 <none> 9100/TCP 14s
service/prometheus-operated ClusterIP None <none> 9090/TCP 7s
NAME CLASS HOSTS ADDRESS PORTS AGE
ingress.networking.k8s.io/kube-prometheus-stack-alertmanager alb alertmanager.ygpark.net k8s-monitoring-cb10304ba1-122800226.ap-northeast-2.elb.amazonaws.com 80 14s
ingress.networking.k8s.io/kube-prometheus-stack-grafana alb grafana.ygpark.net k8s-monitoring-cb10304ba1-122800226.ap-northeast-2.elb.amazonaws.com 80 14s
|
cs |
프로메테우스에 접속해서 UI를 살펴보자.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
|
# ingress 확인
kubectl get ingress -n monitoring kube-prometheus-stack-prometheus
kubectl describe ingress -n monitoring kube-prometheus-stack-prometheus
# 프로메테우스 ingress 도메인으로 웹 접속
echo -e "Prometheus Web URL = https://prometheus.$KOPS_CLUSTER_NAME"
Prometheus Web URL = https://prometheus.ygpark.net
# 웹 상단 주요 메뉴 설명
1. 경고(Alert) : 사전에 정의한 시스템 경고 정책(Prometheus Rules)에 대한 상황
2. 그래프(Graph) : 프로메테우스 자체 검색 언어 PromQL을 이용하여 메트릭 정보를 조회 -> 단순한 그래프 형태 조회
3. 상태(Status) : 경고 메시지 정책(Rules), 모니터링 대상(Targets) 등 다양한 프로메테우스 설정 내역을 확인 > 버전(2.42.0)
4. 도움말(Help)
|
cs |
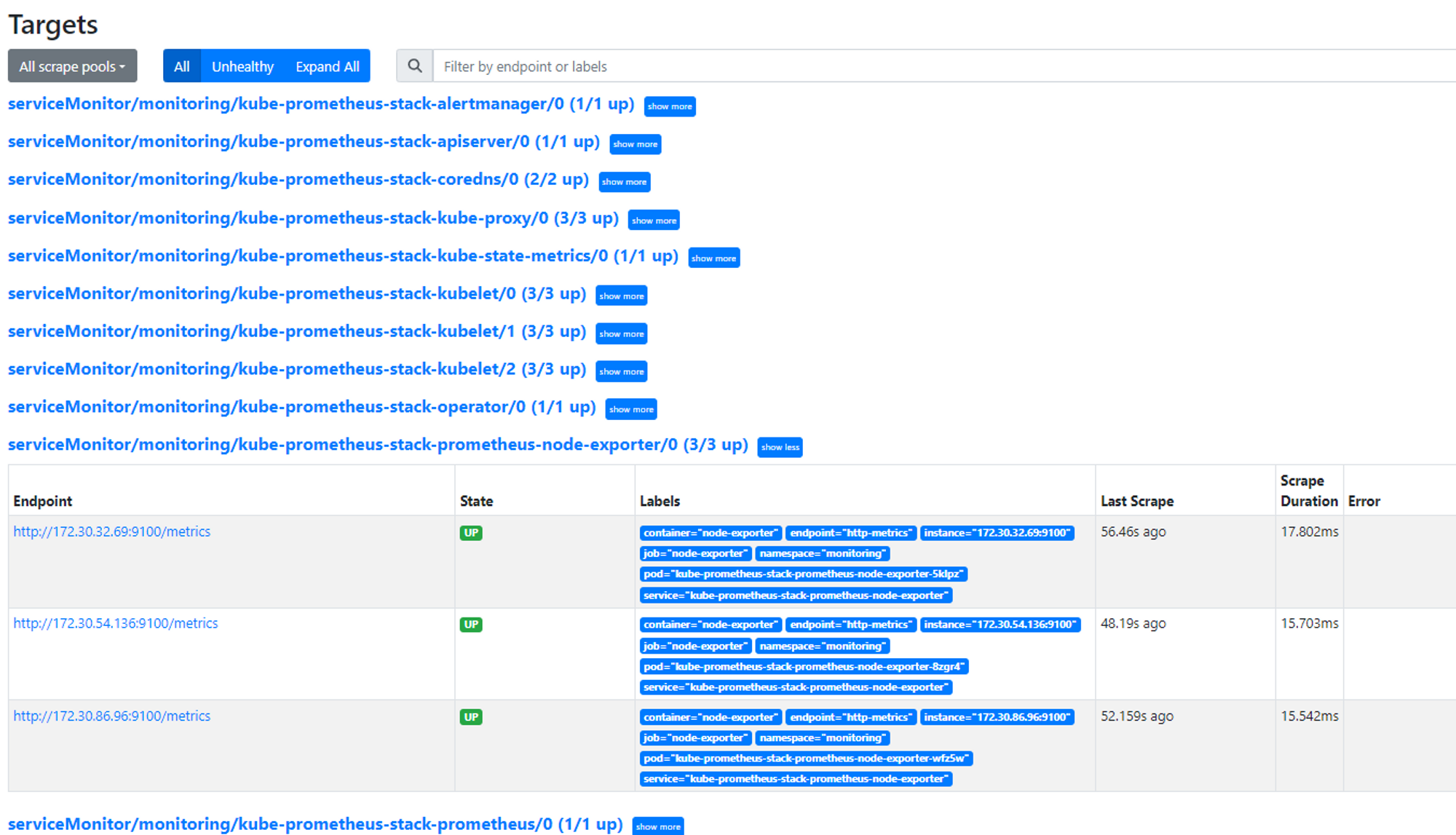
Status 메뉴의 Service Discovery를 보면 리소스 정보를 자동으로 발견해서 메트릭 수집하고 있다. 타겟, 도달설정이 이미 구성되어 있다. 이외의 메트릭을 가져오는 주기, 타임아웃, Alert 관련 설정 등을 볼 수 있다.
2. 그라파나 (Grafana)
그라파나는 시계열 데이터를 볼 수있도록 하는 오픈소스이다. 프로메테우스의 graph에서 보던 답답함을 한번에 해소시켜주는 툴이다. ㅎㅎ 그라파나는 시각화 솔루션으로 데이터 자체를 저장하지 않는다. 실제로 내가 주로 사용하는 Google Cloud에서도 Cloud Monitoring의 저장된 메트릭을 그대로 가져와서 그라파나로 시각화 하기도 한다.
|
1
2
3
4
5
6
7
8
9
|
# ingress 확인
kubectl get ingress -n monitoring kube-prometheus-stack-grafana
kubectl describe ingress -n monitoring kube-prometheus-stack-grafana
# ingress 도메인으로 웹 접속
echo -e "Grafana Web URL = https://grafana.$KOPS_CLUSTER_NAME"
defaultDashboardsTimezone: Asia/Seoul
adminPassword: prom-operator
|
cs |
그라파나에 접속하면 네이게이션 바에서 아래 처럼 구성되어 있는 것을 볼 수 있다.
- Search dashboards : 대시보드 검색
- Starred : 즐겨찾기 대시보드
- Dashboards : 대시보드 전체 목록 확인
- Explore : 쿼리 언어 PromQL를 이용해 메트릭 정보를 그래프 형태로 탐색
- Alerting : 경고, 에러 발생 시 사용자에게 경고를 전달
- Configuration : 설정, 예) 데이터 소스 설정 등
- Server admin : 사용자, 조직, 플러그인 등 설정
- admin : admin 사용자의 개인 설정
Configuration에서 보면 스택의 경우 프로메네우스를 Data sources로 자동 등록한다.
대시보드 사용
Dashboards 항목에서 기본 대시보드가 있고, grafana Labs에서 https://grafana.com/orgs/imrtfm/dashboards 다른 사람들이 만들어 놓은 대시보드를 사용해 볼 수 있다.
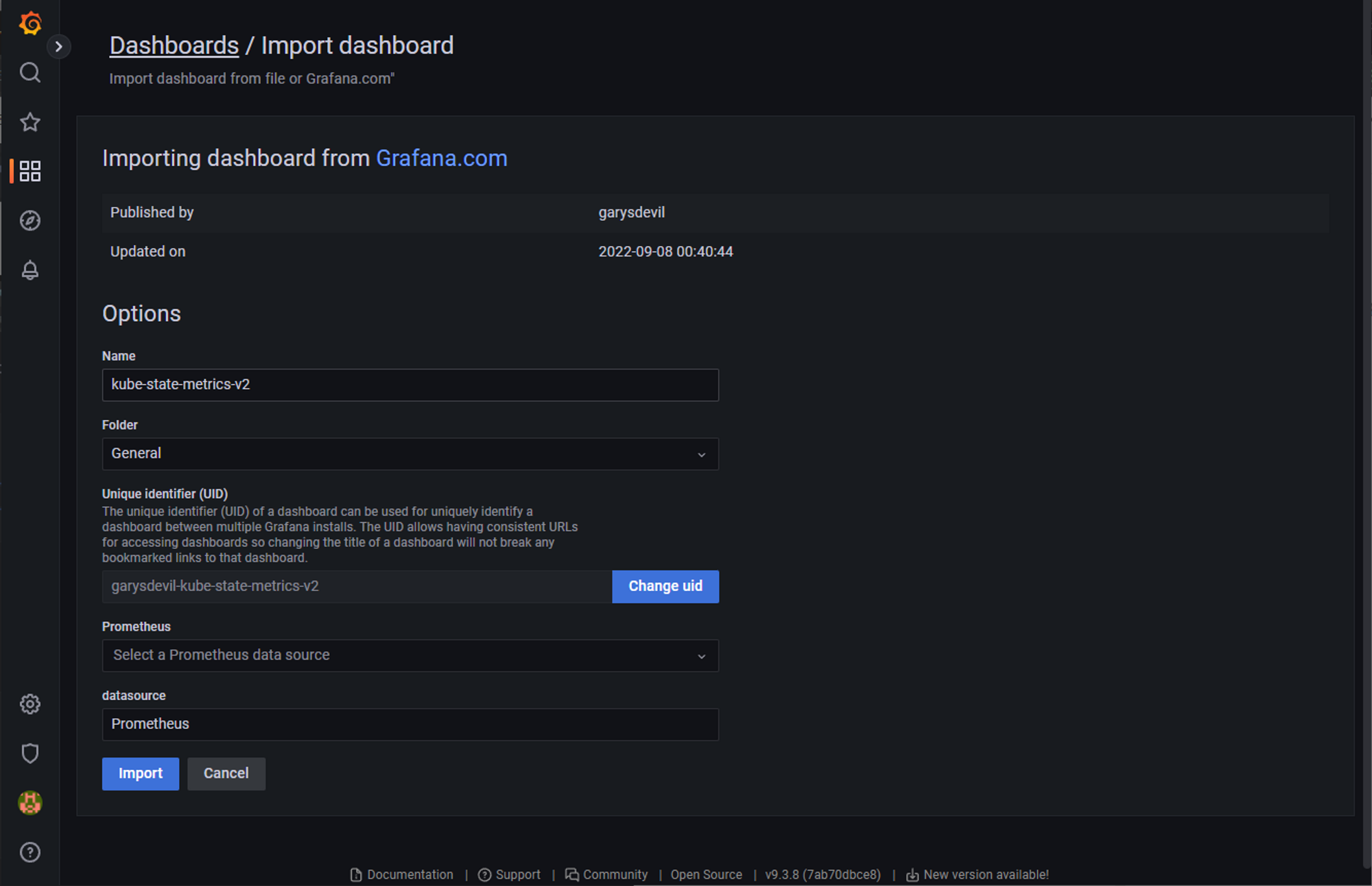
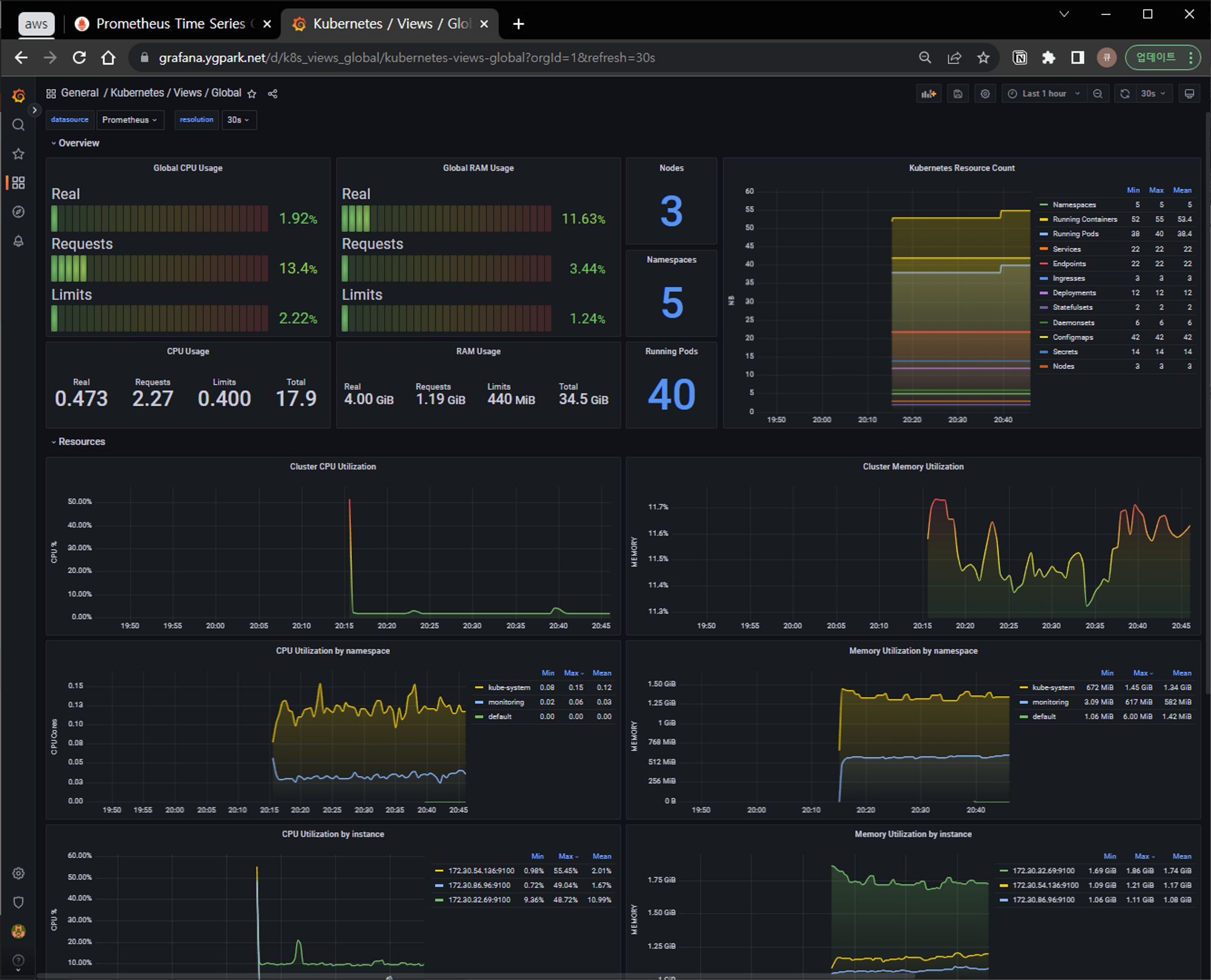
아래 멋진 쿠버네티스 대시보드를 import (import via grafana.com) 쉽게 가져올 수 있다.
3. kwatch
kwatch는 Slack, Discord 같은 채널에 noti를 발행해주는 툴이다. 채널 webhook URL을 넣어 파드를 배포하여 사용한다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
|
# configmap 생성
cat <<EOT > ~/kwatch-config.yaml
apiVersion: v1
kind: Namespace
metadata:
name: kwatch
---
apiVersion: v1
kind: ConfigMap
metadata:
name: kwatch
namespace: kwatch
data:
config.yaml: |
alert:
slack:
webhook: '<채널webhook URL>'
#title:
#text:
pvcMonitor:
enabled: true
interval: 5
threshold: 70
EOT
kubectl apply -f kwatch-config.yaml
configmap/kwatch created
# 배포
kubectl apply -f https://raw.githubusercontent.com/abahmed/kwatch/v0.8.3/deploy/deploy.yaml
|
cs |
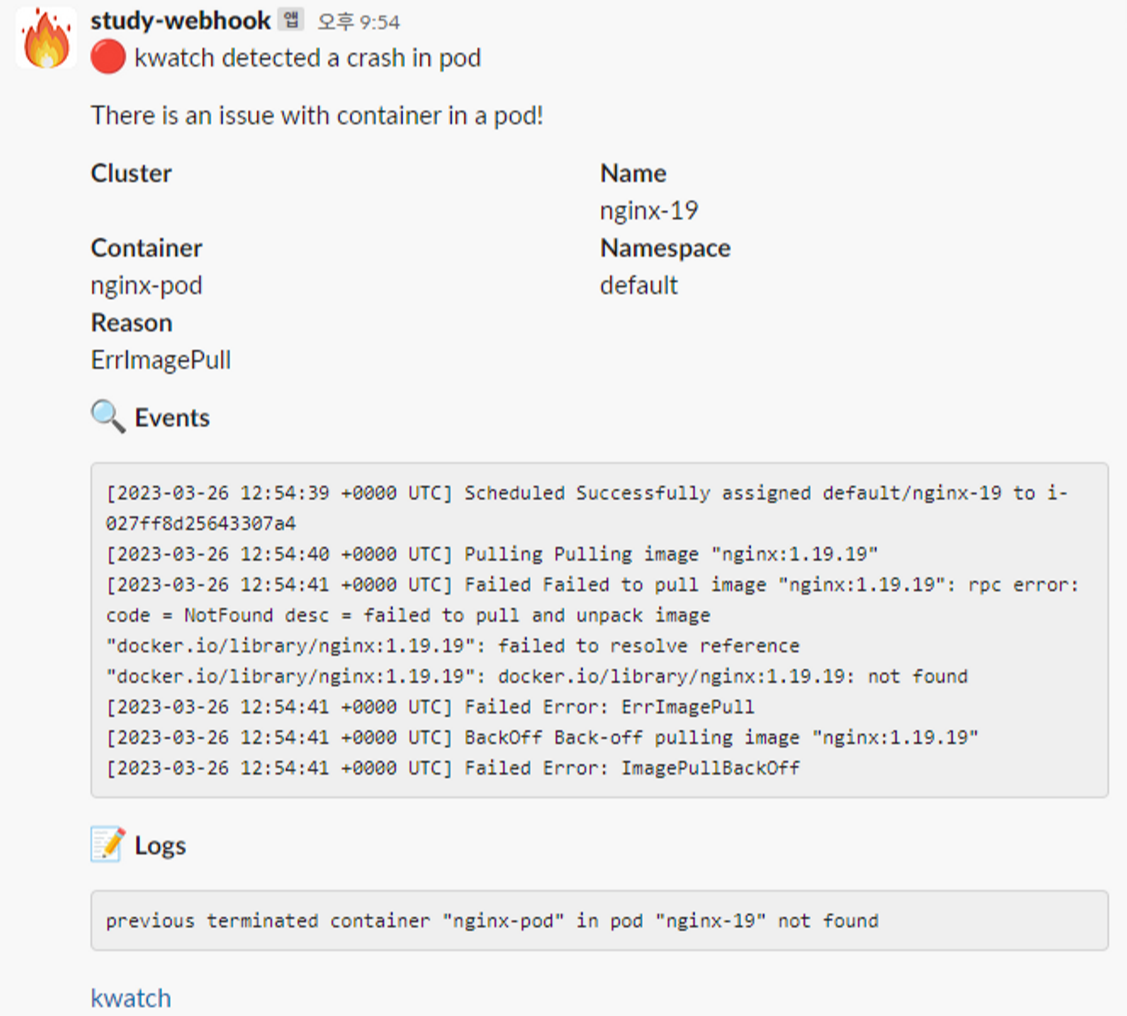
이렇게 이벤트 정보를 채널을 통해 받아볼 수 있다.
4. PLG 스택
Kubernetes의 Log는 어떻게 확인 할까? 보통 사용하는 kubectl logs는 외부에서 명령어로 확인 할 수 있는 방법이다. 하지만 사라진 파드의 로그는 조회 할 수 없고, 로그 파일 최대 크기가 10MiB로 주요 Log 관리가 불가능하다.
PLG Stack은 Promtail + Loki + Grafana로 파드의 로그를 중앙 서버에 저장하고 그라파나로 이를 조회한다.

Promtail은 데몬셋으로 실행되며 각 로그에 로그를 중앙 로키 서버에 전달, Promtail 외에도 도커, FluentD 등 다른 로그수집 에이전트 사용 할 수 있다. 그럼 PLG Stack을 설치 해보자. 우선 Loki 를 설치한다.
Loki 설치
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
|
# 모니터링
kubectl create ns loki
watch kubectl get pod,pvc,svc,ingress -n loki
# Repo 추가
helm repo add grafana https://grafana.github.io/helm-charts
# 파라미터 설정 파일 생성
cat <<EOT > ~/loki-values.yaml
persistence:
enabled: true
size: 20Gi
serviceMonitor:
enabled: true
EOT
# 배포
helm install loki grafana/loki --version 2.16.0 -f loki-values.yaml --namespace loki
W0326 22:26:42.932964 6215 warnings.go:70] policy/v1beta1 PodSecurityPolicy is deprecated in v1.21+, unavailable in v1.25+
NAME: loki
LAST DEPLOYED: Sun Mar 26 22:26:42 2023
NAMESPACE: loki
STATUS: deployed
REVISION: 1
TEST SUITE: None
NOTES:
Verify the application is working by running these commands:
kubectl --namespace loki port-forward service/loki 3100
curl http://127.0.0.1:3100/api/prom/label
(ygpark:N/A) [root@kops-ec2 ~]#
# 설치 확인 : 데몬셋, 스테이트풀셋, PVC 확인
helm list -n loki
NAME NAMESPACE REVISION UPDATED STATUS CHART APP VERSION
loki loki 1 2023-03-26 22:26:42.616994002 +0900 KST deployed loki-2.16.0 v2.6.1
kubectl get pod,pvc,svc,ds,sts -n loki
kubectl get-all -n loki
kubectl get servicemonitor -n loki
kubectl krew install df-pv && kubectl df-pv
k get pods
NAME READY STATUS RESTARTS AGE
nginx-697fd655bf-zpfkt 2/2 Running 0 98m
pod-1 1/1 Running 0 108m
pod-2 1/1 Running 0 108m
# curl 테스트 용 파드 생성
kubectl delete -f ~/pkos/2/netshoot-2pods.yaml
kubectl apply -f ~/pkos/2/netshoot-2pods.yaml
# 로키 gateway 접속 확인
kubectl exec -it pod-1 -- curl -s http://loki.loki.svc:3100/api/prom/label
{}
# (참고) 삭제 시
helm uninstall loki -n loki
kubectl delete pvc -n loki --all
|
cs |
Promtail 설치
Promtail은 로그 파일이 존재하는 서버에 설치되어 로그 파일을 관리하는 서버로 로그를 전송한다. Loki는 Promtail
로부터 로그를 수신한다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
|
# 파라미터 설정 파일 생성
cat <<EOT > ~/promtail-values.yaml
serviceMonitor:
enabled: true
config:
serverPort: 3101
clients:
- url: http://loki-headless:3100/loki/api/v1/push
#defaultVolumes:
# - name: pods
# hostPath:
# path: /var/log/pods
EOT
# 배포
helm install promtail grafana/promtail --version 6.0.0 -f promtail-values.yaml --namespace loki
# (참고) 파드 로그는 /var/log/pods에 저장
ssh -i ~/.ssh/id_rsa ubuntu@api.$KOPS_CLUSTER_NAME ls /var/log/pods
# 설치 확인 : 데몬셋, 스테이트풀셋, PVC 확인
helm list -n loki
kubectl get pod,pvc,svc,ds,sts,servicemonitor -n loki
kubectl get-all -n loki
# (참고) 삭제 시
helm uninstall promtail -n loki
|
cs |
그라파나에서 로그 확인
그라파나 → Configuration → Data Source : 데이터 소스 추가에서 Loki를 추가해준다. HTTP URL은 http://loki-headless.loki:3100 로 설정하고 저장한다.
Loki 로그 확인 대시보드(15141)로 확인 해보면 로그와 발생 빈도를 동시에 확인 할 수 있다.
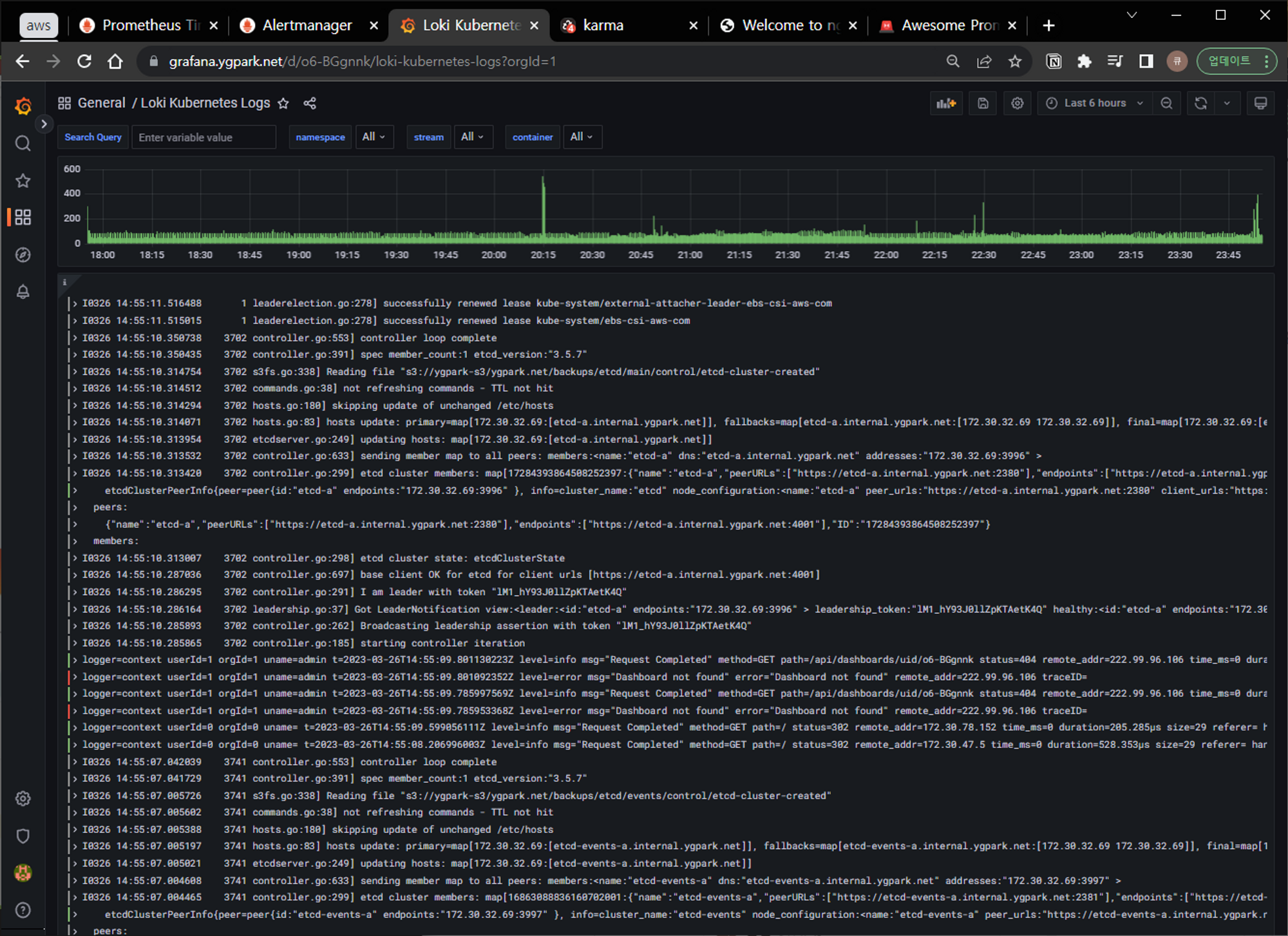
마치며
현업에서는 필요 메트릭만 수집하여 시각화하는 방식으로 사용하곤했는데, 이미 선배님들이 만들어놓은 다양한 대시보드를 가져다 쓸 수 있다니... 어렵게만 생각했던 모니터링, 로깅 시스템을 어떻게 구축하는지 알 수 있었다. 고객사 서비스들을 운영할 때도 적용 가능할 것 같다. Cloud Mornitoring의 대시보드가 로딩이 느려서 답답하기도 했는데 그라파나로 수집해서 모니터링에 적용 할 수도 있을 것 같다.
'스터디 > Kubernetes' 카테고리의 다른 글
| [PKOS] Kubernetes 보안 - kubescape, polaris, RBAC (2/2) (0) | 2023.04.10 |
|---|---|
| [PKOS] Kubernetes 보안 - kubescape, polaris, RBAC (1/2) (0) | 2023.04.09 |
| [PKOS] Kubernetes GitOps 시스템 - Harbor, GitLab, ArgoCD (0) | 2023.03.26 |
| [PKOS] AWS Kubernetes 네트워크, 노드의 Max Pod 제한 (2) | 2023.03.18 |
| [PKOS] kOps를 사용한 Cluster 설치와 기본 Kubernetes 관리 방법 (0) | 2023.03.12 |
이 글은 스터디를 참여하면서 학습한 내용을 중심으로 Kubernetes를 정리하는 연재 글이다. '24단계 실습으로 정복하는 쿠버네티스' 도서 내용을 중심으로 정리하고 있다. 스터디 진도에 맞춰 4~5개의 글을 작성 할 예정이다.
이번 글에서는 Kubernetes의 모니터링, 로깅 시스템을 알아보겠다. 쿠버네티스의 수많은 파드의 메트릭을 확인하고, 문제가 있을 때 로깅을 어떻게 할 수 있을까? 포스팅에서는 모니터링과 로깅을 프로메테우스 (Prometheus), 그라파나(Grafana), 로키(Loki)를 사용해본다.
1. 실습환경 배포
kops 환경을 배포해준다. kops 배포는 [PKOS] kOps를 사용한 Cluster 설치와 기본 Kubernetes 관리 방법 글에 자세히 기술되어 있다. 저번 실습과 같이 이번에도 CPU를 많이 요구하는 시스템으로 비교적 높은 사양의 인스턴스 타입을 사용할 예정이다. 마스터 노드는 t3.medium / 워커 노드는 c5a.2xlarge를 사용했다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
# YAML 파일 다운로드
curl -O https://s3.ap-northeast-2.amazonaws.com/cloudformation.cloudneta.net/K8S/kops-oneclick-f1.yaml
# CloudFormation 스택 배포 : 노드 인스턴스 타입 변경 - MasterNodeInstanceType=t3.medium WorkerNodeInstanceType=c5d.large
aws cloudformation deploy --template-file kops-oneclick-f1.yaml --stack-name mykops --parameter-overrides KeyName=ygpark SgIngressSshCidr=$(curl -s ipinfo.io/ip)/32 MyIamUserAccessKeyID=AKIA6NUKWRMLEXRDE3VA MyIamUserSecretAccessKey='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' ClusterBaseName='ygpark.net' S3StateStore='ygpark-s3' MasterNodeInstanceType=t3.medium WorkerNodeInstanceType=c5a.2xlarge --region ap-northeast-2
# CloudFormation 스택 배포 완료 후 kOps EC2 IP 출력
aws cloudformation describe-stacks --stack-name mykops --query 'Stacks[*].Outputs[0].OutputValue' --output text
13.125.192.64
# 13분 후 작업 SSH 접속
ssh -i /mnt/c/vswork/_pkos2/secret/ygpark.pem ec2-user@$(aws cloudformation describe-stacks --stack-name mykops --query 'Stacks[*].Outputs[0].OutputValue' --output text)
# EC2 instance profiles 에 IAM Policy 추가(attach) : 처음 입력 시 적용이 잘 안될 경우 다시 한번 더 입력 하자! - IAM Role에서 새로고침 먼저 확인!
aws iam attach-role-policy --policy-arn arn:aws:iam::$ACCOUNT_ID:policy/AWSLoadBalancerControllerIAMPolicy --role-name masters.$KOPS_CLUSTER_NAME
aws iam attach-role-policy --policy-arn arn:aws:iam::$ACCOUNT_ID:policy/AWSLoadBalancerControllerIAMPolicy --role-name nodes.$KOPS_CLUSTER_NAME
|
cs |
리소스 메트릭 파이프라인
쿠버네티스의 메트릭 수집을 알아보자. 아래 그림을 보면 노드에 cAdvisor 데몬이 떠있다. cAdvisor은 kubelet에 포함된 컨테이너 메트릭을 수집, 집계, 노출하는 데몬이다. metrics-server가 노드 내부의 kubelet으로부터 리소스 메트릭을 수집한다. kubectl top 명령을 이용하여 리소스 메트릭을 볼 수도 있다.
2. 프로메테우스 (Prometheus)
프로메테우스는 SoundCloud에서 개발한 오픈소스 모니터링, 알림 시스템이다. 쿠버네티스에 사용하기 가장 좋은 툴이고, 프로메테우스 로고는 쿠버네티스와 공통점이 많지만 쿠버네티스를 위해 만들기 시작한 것은 아니라고 한다. 그래도 결과적으로 모두가 인정하는 최적의 쿠버네티스 모니터링 툴이다.
프로메테우스는 TSDB (시계열 데이터베이스)을 적재하여 모니터링을 하고, PromQL이라는 언어로 SQL 쿼리하듯 프로매틱 방식으로 확인할 수 있다. 메트릭을 수집하는 service discovery 지원해서 자동적으로 메트릭 타겟을 등록한다.
구성요소
- the main Prometheus server which scrapes and stores time series data
- client libraries for instrumenting application code
- a push gateway for supporting short-lived jobs
- special-purpose exporters for services like HAProxy, StatsD, Graphite, etc.
- an alertmanager to handle alerts
- various support tools
프로메테우스-스택 설치
모니터링에 필요한 여러 요소를 하나의 스택으로 제공한다. 정책 룰 Prometheus rules, 그라파나 등이 포함되어 있다.
파라미터 파일에는 인그레스 ALB로 노출하고, 타임존 설정과, admin Password를 설정한다. retention / retentionSize은 디스크 용량이 꽉찰 수 있으니 꽉차면 5일 된 것 부터 삭제하도록 설정되어 있다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
|
# 모니터링
kubectl create ns monitoring
watch kubectl get pod,pvc,svc,ingress -n monitoring
# 사용 리전의 인증서 ARN 확인
CERT_ARN=`aws acm list-certificates --query 'CertificateSummaryList[].CertificateArn[]' --output text`
echo "alb.ingress.kubernetes.io/certificate-arn: $CERT_ARN"
alb.ingress.kubernetes.io/certificate-arn: arn:aws:acm:ap-northeast-2:991354587926:certificate/e80b57ba-b808-4390-b17e-c31d4828d29b
# 설치
helm repo add prometheus-community https://prometheus-community.github.io/helm-charts
# 파라미터 파일 생성
cat <<EOT > ~/monitor-values.yaml
alertmanager:
ingress:
enabled: true
ingressClassName: alb
annotations:
alb.ingress.kubernetes.io/scheme: internet-facing
alb.ingress.kubernetes.io/target-type: ip
alb.ingress.kubernetes.io/listen-ports: '[{"HTTPS":443}, {"HTTP":80}]'
alb.ingress.kubernetes.io/certificate-arn: $CERT_ARN
alb.ingress.kubernetes.io/success-codes: 200-399
alb.ingress.kubernetes.io/group.name: "monitoring"
hosts:
- alertmanager.$KOPS_CLUSTER_NAME
paths:
- /*
grafana:
defaultDashboardsTimezone: Asia/Seoul
adminPassword: prom-operator
ingress:
enabled: true
ingressClassName: alb
annotations:
alb.ingress.kubernetes.io/scheme: internet-facing
alb.ingress.kubernetes.io/target-type: ip
alb.ingress.kubernetes.io/listen-ports: '[{"HTTPS":443}, {"HTTP":80}]'
alb.ingress.kubernetes.io/certificate-arn: $CERT_ARN
alb.ingress.kubernetes.io/success-codes: 200-399
alb.ingress.kubernetes.io/group.name: "monitoring"
hosts:
- grafana.$KOPS_CLUSTER_NAME
paths:
- /*
prometheus:
ingress:
enabled: true
ingressClassName: alb
annotations:
alb.ingress.kubernetes.io/scheme: internet-facing
alb.ingress.kubernetes.io/target-type: ip
alb.ingress.kubernetes.io/listen-ports: '[{"HTTPS":443}, {"HTTP":80}]'
alb.ingress.kubernetes.io/certificate-arn: $CERT_ARN
alb.ingress.kubernetes.io/success-codes: 200-399
alb.ingress.kubernetes.io/group.name: "monitoring"
hosts:
- prometheus.$KOPS_CLUSTER_NAME
paths:
- /*
prometheusSpec:
podMonitorSelectorNilUsesHelmValues: false
serviceMonitorSelectorNilUsesHelmValues: false
retention: 5d
retentionSize: "10GiB"
EOT
# 배포
helm install kube-prometheus-stack prometheus-community/kube-prometheus-stack --version 45.7.1 \
--set prometheus.prometheusSpec.scrapeInterval='15s' --set prometheus.prometheusSpec.evaluationInterval='15s' \
-f monitor-values.yaml --namespace monitoring
# 확인
## alertmanager-0 : 사전에 정의한 정책 기반(예: 노드 다운, 파드 Pending 등)으로 시스템 경고 메시지를 생성 후 경보 채널(슬랙 등)로 전송
## grafana : 프로메테우스는 메트릭 정보를 저장하는 용도로 사용하며, 그라파나로 시각화 처리
## prometheus-0 : 모니터링 대상이 되는 파드는 ‘exporter’라는 별도의 사이드카 형식의 파드에서 모니터링 메트릭을 노출, pull 방식으로 가져와 내부의 시계열 데이터베이스에 저장
## node-exporter : 노드익스포터는 물리 노드에 대한 자원 사용량(네트워크, 스토리지 등 전체) 정보를 메트릭 형태로 변경하여 노출
## operator : 시스템 경고 메시지 정책(prometheus rule), 애플리케이션 모니터링 대상 추가 등의 작업을 편리하게 할수 있게 CRD 지원
## kube-state-metrics : 쿠버네티스의 클러스터의 상태(kube-state)를 메트릭으로 변환하는 파드
helm list -n monitoring
NAME ps-NAMESPACE REVISION UPDATED STATUS CHART APP VERSION
kube-prometheus-stackps-monitoring 1 2023-03-26 20:14:22.952127125 +0900 KST deployed kube-prometheus-stack-45.7.1 v0.63.0
kubectl get pod,svc,ingress -n monitoring
kubectl get-all -n monitoring
kubectl get prometheus,alertmanager -n monitoring
kubectl get prometheusrule -n monitoring
kubectl get servicemonitors -n monitoring
kubectl get crd | grep monitoring
|
cs |
모니터링을 해보면 알람 매니저 파드가 확인된다. 프로메테우스가 Pull 방식으로 메트릭을 수집한다.
노드 메트릭을 가져올 수 있도록 node-exporter 파드가 각각 뜬다. node-exporter를 보면 노드 ip에 9100포트가 열려있어서 노드 상태정보를 제공한다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
|
Every 2.0s: kubectl get pod,pvc,svc,ingress -n monitoring Sun Mar 26 20:14:53 2023
NAME READY STATUS RESTARTS AGE
pod/alertmanager-kube-prometheus-stack-alertmanager-0 0/2 ContainerCreating 0 7s
pod/kube-prometheus-stack-grafana-5b69bc5b78-5wwhm 0/3 ContainerCreating 0 14s
pod/kube-prometheus-stack-kube-state-metrics-7c44b8c9c4-bz6c9 0/1 Running 0 13s
pod/kube-prometheus-stack-operator-75b7b9747d-jg7lx 1/1 Running 0 13s
pod/kube-prometheus-stack-prometheus-node-exporter-5klpz 1/1 Running 0 14s
pod/kube-prometheus-stack-prometheus-node-exporter-8zgr4 1/1 Running 0 14s
pod/kube-prometheus-stack-prometheus-node-exporter-wfz5w 1/1 Running 0 14s
pod/prometheus-kube-prometheus-stack-prometheus-0 0/2 PodInitializing 0 7s
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/alertmanager-operated ClusterIP None <none> 9093/TCP,9094/TCP,9094/UDP 7s
service/kube-prometheus-stack-alertmanager ClusterIP 100.70.74.236 <none> 9093/TCP 14s
service/kube-prometheus-stack-grafana ClusterIP 100.71.140.15 <none> 80/TCP 14s
service/kube-prometheus-stack-kube-state-metrics ClusterIP 100.66.23.73 <none> 8080/TCP 14s
service/kube-prometheus-stack-operator ClusterIP 100.68.113.165 <none> 443/TCP 14s
service/kube-prometheus-stack-prometheus ClusterIP 100.66.246.217 <none> 9090/TCP 14s
service/kube-prometheus-stack-prometheus-node-exporter ClusterIP 100.66.25.99 <none> 9100/TCP 14s
service/prometheus-operated ClusterIP None <none> 9090/TCP 7s
NAME CLASS HOSTS ADDRESS PORTS AGE
ingress.networking.k8s.io/kube-prometheus-stack-alertmanager alb alertmanager.ygpark.net k8s-monitoring-cb10304ba1-122800226.ap-northeast-2.elb.amazonaws.com 80 14s
ingress.networking.k8s.io/kube-prometheus-stack-grafana alb grafana.ygpark.net k8s-monitoring-cb10304ba1-122800226.ap-northeast-2.elb.amazonaws.com 80 14s
|
cs |
프로메테우스에 접속해서 UI를 살펴보자.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
|
# ingress 확인
kubectl get ingress -n monitoring kube-prometheus-stack-prometheus
kubectl describe ingress -n monitoring kube-prometheus-stack-prometheus
# 프로메테우스 ingress 도메인으로 웹 접속
echo -e "Prometheus Web URL = https://prometheus.$KOPS_CLUSTER_NAME"
Prometheus Web URL = https://prometheus.ygpark.net
# 웹 상단 주요 메뉴 설명
1. 경고(Alert) : 사전에 정의한 시스템 경고 정책(Prometheus Rules)에 대한 상황
2. 그래프(Graph) : 프로메테우스 자체 검색 언어 PromQL을 이용하여 메트릭 정보를 조회 -> 단순한 그래프 형태 조회
3. 상태(Status) : 경고 메시지 정책(Rules), 모니터링 대상(Targets) 등 다양한 프로메테우스 설정 내역을 확인 > 버전(2.42.0)
4. 도움말(Help)
|
cs |
Status 메뉴의 Service Discovery를 보면 리소스 정보를 자동으로 발견해서 메트릭 수집하고 있다. 타겟, 도달설정이 이미 구성되어 있다. 이외의 메트릭을 가져오는 주기, 타임아웃, Alert 관련 설정 등을 볼 수 있다.
2. 그라파나 (Grafana)
그라파나는 시계열 데이터를 볼 수있도록 하는 오픈소스이다. 프로메테우스의 graph에서 보던 답답함을 한번에 해소시켜주는 툴이다. ㅎㅎ 그라파나는 시각화 솔루션으로 데이터 자체를 저장하지 않는다. 실제로 내가 주로 사용하는 Google Cloud에서도 Cloud Monitoring의 저장된 메트릭을 그대로 가져와서 그라파나로 시각화 하기도 한다.
|
1
2
3
4
5
6
7
8
9
|
# ingress 확인
kubectl get ingress -n monitoring kube-prometheus-stack-grafana
kubectl describe ingress -n monitoring kube-prometheus-stack-grafana
# ingress 도메인으로 웹 접속
echo -e "Grafana Web URL = https://grafana.$KOPS_CLUSTER_NAME"
defaultDashboardsTimezone: Asia/Seoul
adminPassword: prom-operator
|
cs |
그라파나에 접속하면 네이게이션 바에서 아래 처럼 구성되어 있는 것을 볼 수 있다.
- Search dashboards : 대시보드 검색
- Starred : 즐겨찾기 대시보드
- Dashboards : 대시보드 전체 목록 확인
- Explore : 쿼리 언어 PromQL를 이용해 메트릭 정보를 그래프 형태로 탐색
- Alerting : 경고, 에러 발생 시 사용자에게 경고를 전달
- Configuration : 설정, 예) 데이터 소스 설정 등
- Server admin : 사용자, 조직, 플러그인 등 설정
- admin : admin 사용자의 개인 설정
Configuration에서 보면 스택의 경우 프로메네우스를 Data sources로 자동 등록한다.
대시보드 사용
Dashboards 항목에서 기본 대시보드가 있고, grafana Labs에서 https://grafana.com/orgs/imrtfm/dashboards 다른 사람들이 만들어 놓은 대시보드를 사용해 볼 수 있다.
아래 멋진 쿠버네티스 대시보드를 import (import via grafana.com) 쉽게 가져올 수 있다.
3. kwatch
kwatch는 Slack, Discord 같은 채널에 noti를 발행해주는 툴이다. 채널 webhook URL을 넣어 파드를 배포하여 사용한다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
|
# configmap 생성
cat <<EOT > ~/kwatch-config.yaml
apiVersion: v1
kind: Namespace
metadata:
name: kwatch
---
apiVersion: v1
kind: ConfigMap
metadata:
name: kwatch
namespace: kwatch
data:
config.yaml: |
alert:
slack:
webhook: '<채널webhook URL>'
#title:
#text:
pvcMonitor:
enabled: true
interval: 5
threshold: 70
EOT
kubectl apply -f kwatch-config.yaml
configmap/kwatch created
# 배포
kubectl apply -f https://raw.githubusercontent.com/abahmed/kwatch/v0.8.3/deploy/deploy.yaml
|
cs |
이렇게 이벤트 정보를 채널을 통해 받아볼 수 있다.
4. PLG 스택
Kubernetes의 Log는 어떻게 확인 할까? 보통 사용하는 kubectl logs는 외부에서 명령어로 확인 할 수 있는 방법이다. 하지만 사라진 파드의 로그는 조회 할 수 없고, 로그 파일 최대 크기가 10MiB로 주요 Log 관리가 불가능하다.
PLG Stack은 Promtail + Loki + Grafana로 파드의 로그를 중앙 서버에 저장하고 그라파나로 이를 조회한다.
Promtail은 데몬셋으로 실행되며 각 로그에 로그를 중앙 로키 서버에 전달, Promtail 외에도 도커, FluentD 등 다른 로그수집 에이전트 사용 할 수 있다. 그럼 PLG Stack을 설치 해보자. 우선 Loki 를 설치한다.
Loki 설치
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
|
# 모니터링
kubectl create ns loki
watch kubectl get pod,pvc,svc,ingress -n loki
# Repo 추가
helm repo add grafana https://grafana.github.io/helm-charts
# 파라미터 설정 파일 생성
cat <<EOT > ~/loki-values.yaml
persistence:
enabled: true
size: 20Gi
serviceMonitor:
enabled: true
EOT
# 배포
helm install loki grafana/loki --version 2.16.0 -f loki-values.yaml --namespace loki
W0326 22:26:42.932964 6215 warnings.go:70] policy/v1beta1 PodSecurityPolicy is deprecated in v1.21+, unavailable in v1.25+
NAME: loki
LAST DEPLOYED: Sun Mar 26 22:26:42 2023
NAMESPACE: loki
STATUS: deployed
REVISION: 1
TEST SUITE: None
NOTES:
Verify the application is working by running these commands:
kubectl --namespace loki port-forward service/loki 3100
curl http://127.0.0.1:3100/api/prom/label
(ygpark:N/A) [root@kops-ec2 ~]#
# 설치 확인 : 데몬셋, 스테이트풀셋, PVC 확인
helm list -n loki
NAME NAMESPACE REVISION UPDATED STATUS CHART APP VERSION
loki loki 1 2023-03-26 22:26:42.616994002 +0900 KST deployed loki-2.16.0 v2.6.1
kubectl get pod,pvc,svc,ds,sts -n loki
kubectl get-all -n loki
kubectl get servicemonitor -n loki
kubectl krew install df-pv && kubectl df-pv
k get pods
NAME READY STATUS RESTARTS AGE
nginx-697fd655bf-zpfkt 2/2 Running 0 98m
pod-1 1/1 Running 0 108m
pod-2 1/1 Running 0 108m
# curl 테스트 용 파드 생성
kubectl delete -f ~/pkos/2/netshoot-2pods.yaml
kubectl apply -f ~/pkos/2/netshoot-2pods.yaml
# 로키 gateway 접속 확인
kubectl exec -it pod-1 -- curl -s http://loki.loki.svc:3100/api/prom/label
{}
# (참고) 삭제 시
helm uninstall loki -n loki
kubectl delete pvc -n loki --all
|
cs |
Promtail 설치
Promtail은 로그 파일이 존재하는 서버에 설치되어 로그 파일을 관리하는 서버로 로그를 전송한다. Loki는 Promtail
로부터 로그를 수신한다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
|
# 파라미터 설정 파일 생성
cat <<EOT > ~/promtail-values.yaml
serviceMonitor:
enabled: true
config:
serverPort: 3101
clients:
- url: http://loki-headless:3100/loki/api/v1/push
#defaultVolumes:
# - name: pods
# hostPath:
# path: /var/log/pods
EOT
# 배포
helm install promtail grafana/promtail --version 6.0.0 -f promtail-values.yaml --namespace loki
# (참고) 파드 로그는 /var/log/pods에 저장
ssh -i ~/.ssh/id_rsa ubuntu@api.$KOPS_CLUSTER_NAME ls /var/log/pods
# 설치 확인 : 데몬셋, 스테이트풀셋, PVC 확인
helm list -n loki
kubectl get pod,pvc,svc,ds,sts,servicemonitor -n loki
kubectl get-all -n loki
# (참고) 삭제 시
helm uninstall promtail -n loki
|
cs |
그라파나에서 로그 확인
그라파나 → Configuration → Data Source : 데이터 소스 추가에서 Loki를 추가해준다. HTTP URL은 http://loki-headless.loki:3100 로 설정하고 저장한다.
Loki 로그 확인 대시보드(15141)로 확인 해보면 로그와 발생 빈도를 동시에 확인 할 수 있다.
마치며
현업에서는 필요 메트릭만 수집하여 시각화하는 방식으로 사용하곤했는데, 이미 선배님들이 만들어놓은 다양한 대시보드를 가져다 쓸 수 있다니... 어렵게만 생각했던 모니터링, 로깅 시스템을 어떻게 구축하는지 알 수 있었다. 고객사 서비스들을 운영할 때도 적용 가능할 것 같다. Cloud Mornitoring의 대시보드가 로딩이 느려서 답답하기도 했는데 그라파나로 수집해서 모니터링에 적용 할 수도 있을 것 같다.
'스터디 > Kubernetes' 카테고리의 다른 글
| [PKOS] Kubernetes 보안 - kubescape, polaris, RBAC (2/2) (0) | 2023.04.10 |
|---|---|
| [PKOS] Kubernetes 보안 - kubescape, polaris, RBAC (1/2) (0) | 2023.04.09 |
| [PKOS] Kubernetes GitOps 시스템 - Harbor, GitLab, ArgoCD (0) | 2023.03.26 |
| [PKOS] AWS Kubernetes 네트워크, 노드의 Max Pod 제한 (2) | 2023.03.18 |
| [PKOS] kOps를 사용한 Cluster 설치와 기본 Kubernetes 관리 방법 (0) | 2023.03.12 |